Video of Ryzen Master’s Dynamic Local Mode
UPDATE: Bitsum is testing our own Dynamic Local Mode implementation – See this forum thread for more information.
Here at Bitsum we’ve been closely following the AMD Threadripper 2nd gen releases. As has been well reported on tech sites, the core heavy 2990wx and 2970wX have an unusual configuration where only 2 of the 4 dies have direct access to channels of system memory (DMA). The other two dies must pass all memory and PCIe requests through the Infinity Fabric that links the CPU dies together. This results in additional memory access latency for 2 of the dies, or 1/2 the CPU cores.
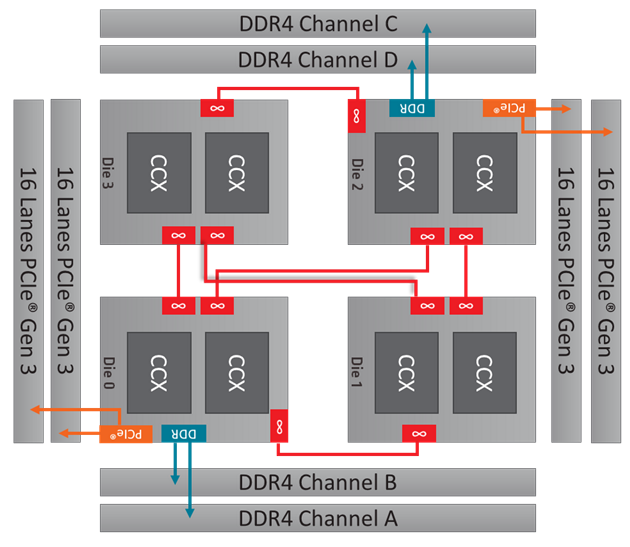
AMD exposes each die as a NUMA node. The NUMA mapping is thus that 2 of the nodes have *zero* node local memory! Node local memory is the memory closest to a CPU, having the lowest latency. Therefore, the configuration for 4 memory channels is:
Node 0: [1/2 of memory local] - low latency
Node 1: [0 memory local] - higher latency
Node 2: [1/2 of memory local] - low latency
Node 3: [0 memory local] - higher latency
Note: For Threadripper processors, the DMA CPU cores are the first half, starting at 0 and numbered sequentially. In the case of the 2990wx, node 0 represents logical cores cores 0-15 and node 2 represents 16-31.
NUMA nodes 0 and 2 each have access to two of the four possible memory channels, so each has direct access to half the system memory. NUMA nodes 1 and 3 must pass all requests through the Infinity Fabric.
Linux is able to handle this esoteric NUMA configuration much better than Windows. It seems that the Windows scheduler was designed with the understandable assumption that every NUMA node has local memory. This odd case of NUMA nodes without any local memory causes the Windows scheduler to assign threads without regard to the more optimal dies in the 2990wx and 2970wx.
AMD initially combated this by allowing a user to disable the less efficient NUMA nodes so that performance critical applications can always run on the more optimal CPU dies. This same operation can be done with our Process Lasso. However, disabling half the system’s CPU cores is not ideal and is problematic when an application’s thread load grows beyond that limitation.
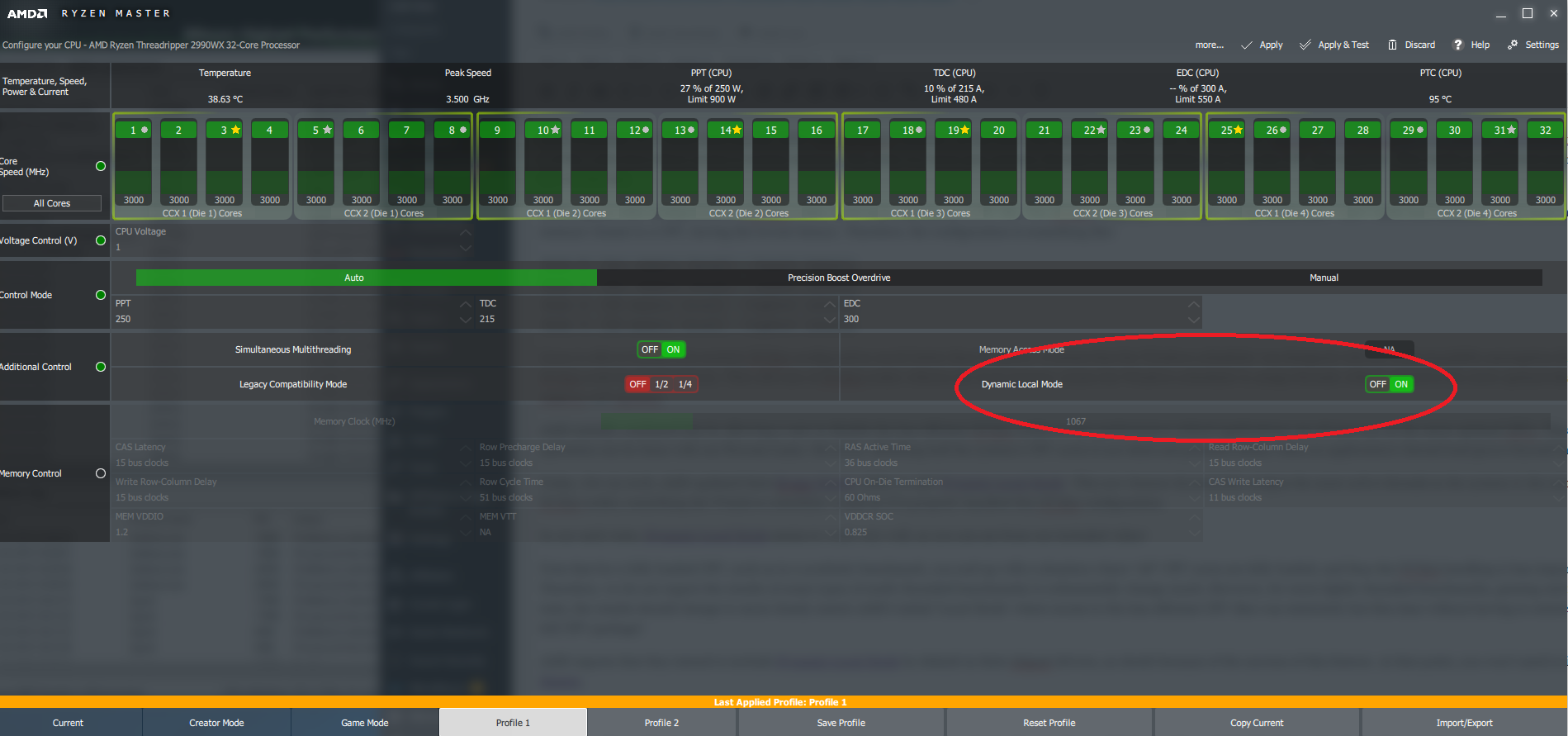
Today, Oct 29 2018, AMD updated their Ryzen Master utility to add ‘Dynamic Local Mode‘. This new feature dynamically assigns the most active threads in the system to the more efficient NUMA nodes; something the Windows scheduler would do if it properly handled this NUMA configuration.
In our early tests, Dynamic Local Mode seems to work very well, as you can see from our embedded video!
AMD reports that they intend to include Dynamic Local Mode by default in their chipset drivers, no doubt because of the success of this feature. At that point, you won’t need to install Ryzen Master.
See our early tests of Dynamic Load Mode below:
For a fully loaded CPU, such as some types of synthetic benchmarks, NUMA handling is less important since there aren’t more optimal cores free to choose from. Therefore, we do not expect the results of some types of multi-threaded benchmarks to substantially change. However, for more lightly threaded benchmarks, gaming and real-world tests, the results should change to more closely match AMD’s initial ‘Local Mode’ where access to the less efficient CPU dies was restricted; but this time without having to restrict access to the full CPU package!
Footnote: Ryzen Master has an annoying UAC elevation prompt on user login. You can bypass this by creating a Task Scheduler entry for it, then opening the properties of that task and checking ‘Run as administrator’.
Discover more from Bitsum
Subscribe to get the latest posts sent to your email.