Coreprio
Coreprio is a free, open source CPU optimization utility for the AMD 2990wx and 2970wx processors on Windows. It offers two features: (1) our implementation of AMD’s Dynamic Local Mode and (2) our new ‘NUMA Dissociater’.
Introduction
Coreprio’s Dynamic Local Mode (DLM) is more configurable and robust than AMD’s implementation, allowing the user to set the prioritized CPU affinity, (software) thread count, refresh rate, and which processes to include/exclude.
Dynamic Local Mode was conceived for the AMD Threadripper 2990wx and 2970wx CPUs, addressing their asymmetric die performance. There are potentially other use cases.
DLM works by dynamically migrating the most active software threads to the prioritized CPU cores. The Windows CPU scheduler is free to choose specifically where within that set of CPUs to assign threads.
Since no hard CPU affinity is set, applications are still free to expand across the entire CPU. For this reason, we call it a prioritized soft CPU affinity.
DLM is designed for loads that don’t max out all available CPU cores. Applications that put a full load across the entire CPU could perform marginally worse. This is because when the entire CPU is loaded, there are no CPU cores to prioritize threads to since all must be utilized. Thus it may be ideal to exclude some highly multi-threaded applications.
Coreprio also offers an experimental feature named ‘NUMA Dissociater‘. The NUMA Dissociater is confirmed to work on EPYC 7551 and TR 2970/2990, but may work on other HCC NUMA platforms.
You can see details of Coreprio’s thread management by using the console utility or an elevated instance of DebugView with ‘Capture Global Win32‘ enabled.
Dynamic Local Mode: Background
When the ThreadRipper 2990wx and 2970wx were developed, AMD had to make due with the 4 memory channels available in the TR4 socket motherboards to retain chipset compatibility.
This means that 2 of the 4 dies in these CPUs do not have memory channels attached to them. They must instead pass all memory requests through the Infinity Fabric chip interconnect.
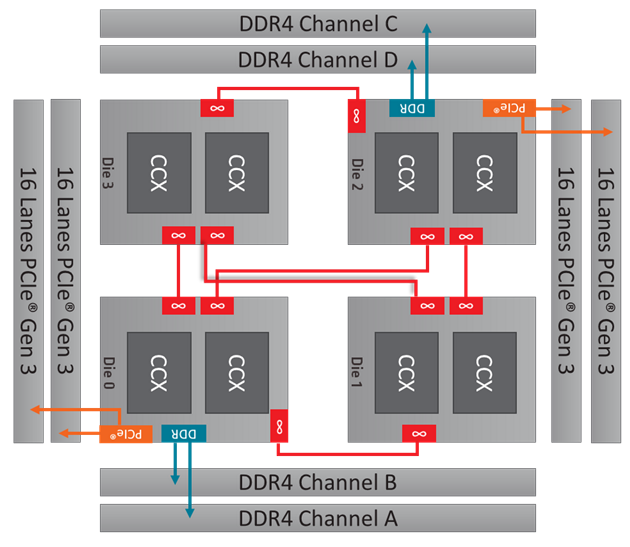
Due to this indirect I/O access, the memory (and PCIe) latency for two dies ends up higher than the other two. That equates to one half of the system total cores.
By default, each die is exposed as a NUMA node. The two more optimal dies will each have 2 memory channels of node local memory. The two less optimal dies will have no local memory. This is a bit esoteric, as NUMA designs are more typically used to associate the memory closest to a CPU package. In this way, the operating system knows what memory to use for threads running on specific CPUs.
This lack of any node local memory throws Windows for a loop. The OS doesn’t realize it needs to schedule threads on the more optimal dies first, as it instead focuses on matching memory to CPUs. Since there is no memory to match to the less efficient dies, it simply schedules threads equally across the entire CPU package.
Pending scheduler work from Microsoft that may never come, AMD developed a kludge called Dynamic Local Mode. This monitors running threads and suggests to the OS that those with the highest activity be scheduled on the more efficient CPU dies.
AMD’s Dynamic Local Mode is included with their Ryzen Master software, and expected to eventually be included in the chipset drivers.
Here at Bitsum, we decided to develop our own implementation of Dynamic Local Mode. This allows tuning and customization beyond what could be accomplished with AMD’s offering. Going forward, there are lots of possibilities.
Enter Coreprio … Bitsum’s own Dynamic Local Mode.
Dynamic Local Mode: How It Works
Coreprio works by monitoring all threads on the system and moving those with the highest activity to the more optimal CPU dies. It still lets Windows choose where exactly to schedule the threads on the more optimal dies. When thread activity diminishes, the thread affinity is changed back to all dies.
We call the more optimal CPU cores the prioritized affinity. The number of threads that should be moved to that chipset at any given time is the thread count. The rate at which Coreprio makes these changes is the refresh rate.
DLM is designed for loads that don’t max out all available CPU cores. Applications that put a full load across the entire CPU could perform marginally worse. This is because when the entire CPU is loaded, there are no CPU cores to prioritize threads to since all must be utilized. Thus it may be ideal to exclude some highly multi-threaded applications.
NUMA Dissociater: Background
This is a curious discovery and feature still under investigation.
Wendell at Level1Techs bought a new EPYC 7551 to play with and found the same sub-optimal benchmark results that were seen on the 2990wx. Most curiously, when the EPYC system was set to UMA mode, the performance issues disappeared, and certain benchmarks, specifically, Indigo and 7-Zip, saw 2X performance gains, bringing them up to par with their theoretical performance based on their core count, and actual performance seen in linux.
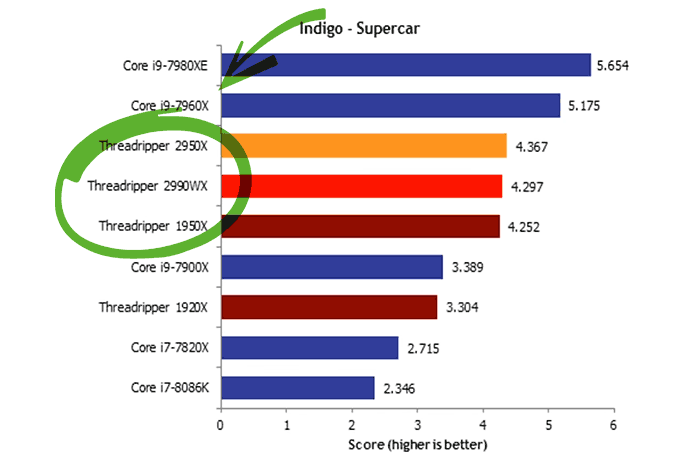
2990wx Indigo Performance Regression. Image from Hexus.net
This curious improvement by disabling NUMA led Wendell to believe the previously noted issues on the 2990wx were not solely due to 2 dies not having direct memory channels, and instead we were seeing the same effect on both platforms.
Back in NUMA mode, he noticed that changing the CPU affinity of select benchmarks (e.g. Indigo) caused them to mysteriously increase in performance. This is why he previously saw the performance gains after removing core 0 on the 2990wx Indigo benchmarks way back when. Ian at Anandtech later tested core 0 removal on the 2990wx, but didn’t find the same impact. It turns out the reason was because the CPU affinity has to be changed after the process starts; the effect is not seen when the CPU affinity is assigned during process creation.
Dumping the thread info in real-time revealed the thread ideal processors are doled out differently after a fix is applied to a process, no longer constrained to a single NUMA node, but that should not itself been any problem if the scheduler wasn’t brain-dead. The thread ideal processors are supposed to be just a hint the scheduler uses, not gospel.
What is the issue?
Nobody knows. Or at least nobody has communicated such. Whether it is core thrashing, a memory channel bottleneck inherent to the NUMA allocation strategy, we don’t know. No theories have panned out that point to a definitive cause, leading to the speculation it may simply be some bug or quirk deep in the Windows scheduler.
What is the ‘fix’?
The ‘fix’ is bizarrely imprecise. For affected processes, a call to SetProcessAffinityMask, without even changing the affinity (e.g. all CPUs to all CPUs), resolves the performance issue – at least most of the time. Our best guess is that the preferred NUMA node for the process is removed, causing the Windows scheduler to change behavior, as evidenced by the thread ideal processor selections, and more importantly the massive change in performance.
What CPUs are impacted?
The TR2990wx, TR2970wx, and EPYC 7551 have been confirmed. It is not clear whether this applies exclusively to AMD processors.
It has been difficult to reach solid conclusions because the behavior is so bizarre. Hopefully the community can contribute to our understanding of the details and scope of this sub-optimal behavior.
In any event, ‘NUMA dissociater’ addresses this deficiency, as evidenced by ~100% gains in Indigo and select other benchmarks.
Consistency Issues!
It must be noted that the NUMA Dissociater doesn’t ‘take’ sometimes, particularly on the 2990wx. EPYC is less impacted. On the 2990wx, restarting the Indigo process 10 times, 50% of those instances won’t result in the ‘fast’ edition. This is still a massive improvement, as without the NUMA Dissociater, 100% of runs will be slow. This is not any bug in Coreprio, but something inherent to the nature of the performance issue. As we learn more about the fundamental issue we will presumably be able to improve consistency. As of this date, it is not clear that anyone, even AMD or Microsoft, understands what is going on. While we have numerous hypothesis, none have been proven.
Coreprio Usage
Coreprio can run as either a system service and managing user interface, or a stand-alone console mode utility.
The Coreprio Installation Package contains:
- corepriow.exe – GUI, resident in system tray
- cpriosvc.exe – Coreprio service
- coreprio.exe – Coreprio console mode
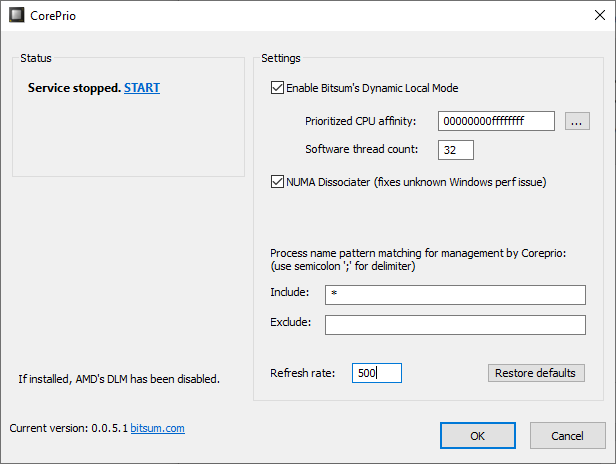
The Coreprio (GUI) can be launched from the start menu or by running corepriow.exe. It allows you to start and stop the service, and tweak parameters. It resides in the system tray, represented by an icon of a CPU.
The prioritized affinity defaults to the first half of logical cores, and the count of threads to prioritize is half the total logical core count (or the number of logical CPUs in the prioritized affinity).
‘Threads to prioritize‘ (formerly ‘thread count’) is the maximum number of software threads that should be moved to the prioritized CPU set at any given time. This field should generally not exceed the number of CPU cores in the prioritized CPU affinity mask.
Limited debug output from the service can be viewed with an elevated instance of DebugView and ‘Capture / Capture Global Win32’ checked. However, it is recommended the console mode utility be used if you want to see output.
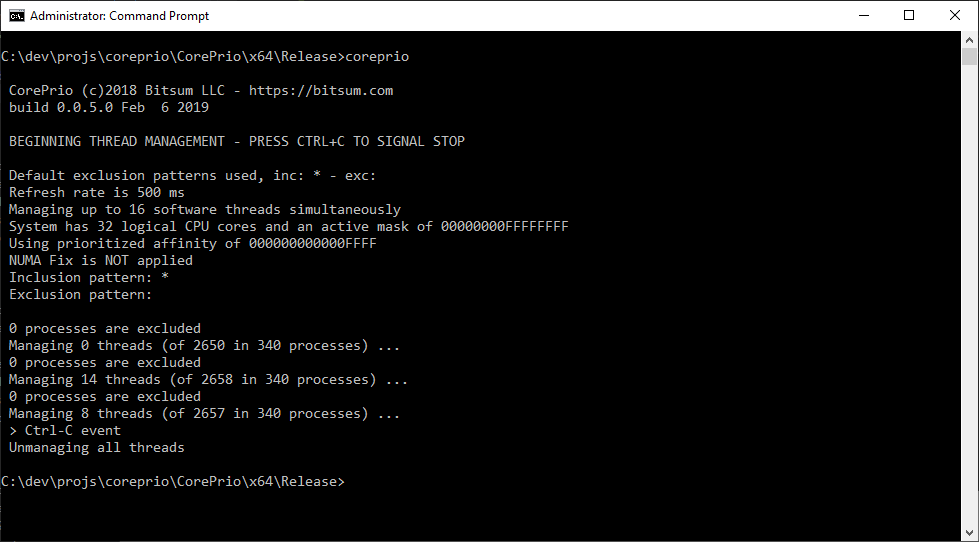
Alternatively, the Coreprio debug console, coreprio.exe, can be run without parameters to use the defaults or saved settings. Command line parameters are provided to over-ride those values.
When the console mode utility is run, the Coreprio service is stopped. The running algorithm is hosted by the Coreprio console app. That is to say, this is not output from the service, but is the same code running instead in the console.
Console usage is described below:
USAGE: CorePrio [-i refresh_rate_ms] [-n sw_thread_count] [-f] [-a prioritized_affinity]
[-l,--inclusions include_pattern] [-x,--exclusions exclude_pattern]
Defaults:
-i (rate) -> 500 (ms)
-n (threads) -> half of logical core count
-a (affinity) -> first half of logical cores
-l,--inclusions -> '*'
-x,--exclusions-> ''
Inclusion and exclusion patterns are semicolon ';' delimited. Inclusions processed first, then exclusions.
The -f parameter enforces an experimental performance fix for Windows NUMA and disables DLM.
Example: CorePrio -i 500 -n 32 -a 00000000ffffffff --inclusions * --exclusions someapp.exe;more.exe
Runs CorePrio with at a refresh rate of 500 ms, managing 32 threads, with prioritized CPU affinity of 0-31.
It includes all processes () and exclusions those matching 'someapp.exe' or 'more*.exe'.
Support this work
This is a FREEWARE offering. You can support this work by purchasing a license for Process Lasso Pro. You may also donate any arbitrary amount here. Your support is essential to the continued R&D of this, and other, Bitsum projects.
Discover more from Bitsum
Subscribe to get the latest posts sent to your email.